
Scrapy 爬取图片,本章采用半自定义方法,使用scrapy爬虫爬取图片。
这里我们以美食杰为例,爬取它的图片作为演示,这里只爬取一页,如图所示:
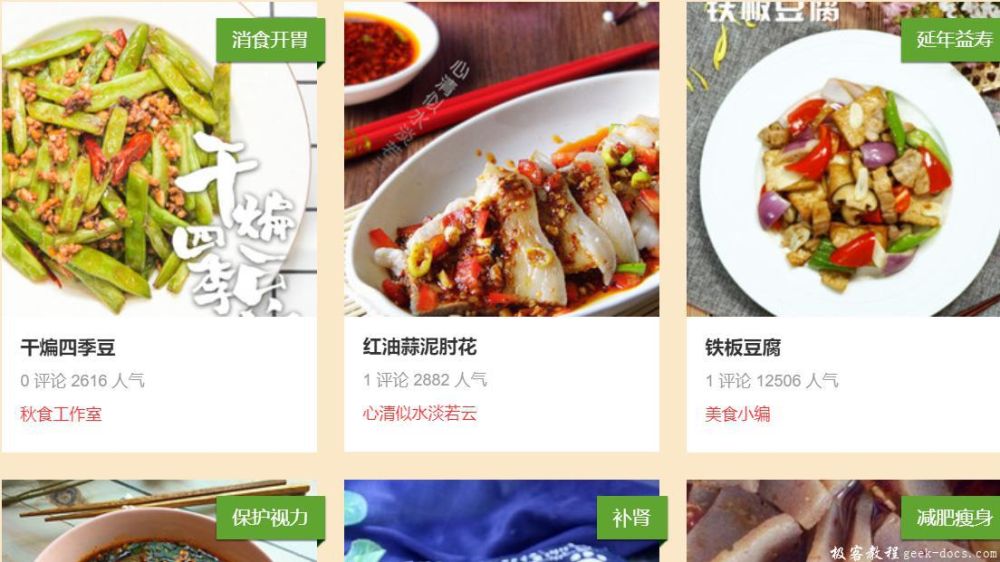
爬取图片的工作分成如下六个步骤来完成
创建项目
首先我们在命令行进入到我们要创建的目录,执行如下指令创建爬虫项目。
scrapy startproject meishi
输出结果如图所示:

生成爬虫
然后执行指令cd meishi,进入到meishi文件夹,执行如下指令生成爬虫。
scrapy genspider mei meishij.net
输出结果如图所示:

xpath抓取图片
点进上图所示的mei.py文件,这里需要注意,要将start_urls[]改为我们要爬取的Url地址:
https://www.meishij.net/china-food/caixi/chuancai/
这里使用xpath爬取图片,如代码所示:
class MeiSpider(scrapy.Spider):
name = 'mei'
allowed_domains = ['meishij.net']
start_urls = ['https://www.meishij.net/china-food/caixi/chuancai/']
def parse(self, response):
src_list = response.xpath('//div[@class="listtyle1"]/a/img/@src').extract()
for src in src_list:
print(src)
执行爬虫程序,查看结果是否符合预期:
scrapy crawl mei --nolog
执行结果如图所示,说明程序符合预期

配置item文件
进入到items文件,用它来处理刚刚得到的文件
class MeishiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
src = scrapy.Field()
进入到mei.py文件,引入items这个文件的函数,并进行输出,因为src是图片,所以要用[]括起来
import scrapy
from ..items import MeishiItem
class MeiSpider(scrapy.Spider):
name = 'mei'
allowed_domains = ['meishij.net']
start_urls = ['https://www.meishij.net/china-food/caixi/chuancai/']
def parse(self, response):
src_list = response.xpath('//div[@class="listtyle1"]/a/img/@src').extract()
for src in src_list:
item = MeishiItem()
item['src'] = [src]
yield item
配置settings文件
在settings.py里进行设置,大致在67行前后的位置,自定义下载。
IMAGES_STORE = '' 里面写图片保存的路径
IMAGES_URLS_FIELD='' 里面写接收图片的变量
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 'meishi.pipelines.MeishiPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':1
}
IMAGES_STORE = 'images'
IMAGES_URLS_FIELD = 'src'
测试结果
在命令行执行指令 scrapy crawl mei 点击确认,看到如图所示,恭喜你,图像爬取成功!

版权声明:本页面内容旨在传播知识,为用户自行发布,若有侵权等问题请及时与本网联系,我们将第一时间处理。E-mail:284563525@qq.com



